I’ve recently gotten more and more involved with the Wine project. I am a gamer, after all, and having only a Mac laptop and OS X makes it somewhat hard to play games. While debugging wine logs, I’ve encountered a problem many face when using +relay. You can’t just ignore those 4 GB logs, as they often contain the exact reason, or more precisely, the exact location your game/software crashed. I use Sublime Text to read those, it is so far the most performant editor when handling huge text files, quickly and easily dealing with gigabytes of logs. Consider me impressed.
The idea
So, I had this wonderful idea, call it an inspiration or an excuse to practice std::thread, create a multithreaded wine log parser! Here is an example of a +relay log, so you understand where I’m coming from.
0088:Call KERNEL32.lstrcmpA(44052378 "1.3.6.1.4.1.311.10.9.1",b56f7760 "1.2.840.10045.2.1") ret=44039072 0047:Ret msvcr100.memset() retval=8fadb1f0 ret=004095e5 006b:Ret KERNEL32.IsDebuggerPresent() retval=00000000 ret=05fcea5a 0009:Call window proc 0x3f0fe2 (hwnd=0x10070,msg=WM_TIMER,wp=00000001,lp=00000000) 008b:Ret ntdll.RtlReAllocateHeap() retval=16bb33e0 ret=44023114 0088:Ret KERNEL32.lstrcmpA() retval=00000001 ret=44039072
Every call to a wine function is there, with it’s parameters, and every return is too. The debug lines usually contain the return address, which I use to my advantage in the parser. If there was no problem in the wine function, it should print a return call. I’m looling at you, msvcr100.ldiv()!
- My goal: Parse the log and match very Call to their corresponding Ret. Remove matching pairs, so I can analyze the Calls that don’t Return for debugging purpose. Those are potentially responsible for the crash.
- My idea: Queue up all the Call lines in a thread, when a Ret line is found process all the stored Calls. In a multithreaded fashion of course.
- The conclusion: If you are here for the parser, let me spare you the time. It is **slowwwwww! **Why? Because the bottleneck isn’t the parsing (it could be), it is the file reading… I hope I saved you some time there ;)
This little project was fun, insightful and a really great way to prototype some threading concepts. I learned a lot of new things, and am more comfortable with the standard library threads. All in all, even though it doesn’t really work for big logs, I am satisfied. So, lets make a thread pool tutorial out of this!
Thread pools and thread objects
Here is some more general information on what I am about to show you. I used a thread pool object, that stores thread objects in a vector. These thread objects store work functors, also in a vector. At first I used an std::function vector for the workload, but soon realized I needed a bit more than that, since I need to refer to the previously read Call string.
There was no real need of encapsulating everything in a thread pool object, It simply makes it much more reusable in the future, as this is the most generalized structure. The deeper you go, the more my classes are specialized. Since this is a prototype, I simply coded everything inline and used structs for my classes. I didn’t want to deal with getters and setters etc. This code needs a lot of massaging if you are going to use it a real-world application.
Lets do dis
Everything is coded in a main.cpp file. You can of course separate the different classes into their own files. First, lets get the casual stuff out of the way, shall we.
Includes & global variables.
#include <algorithm>
#include <chrono>
#include <condition_variable>
#include <functional>
#include <fstream>
#include <iomanip>
#include <iostream>
#include <mutex>
#include <string>
#include <thread>
#include <vector>
/* This mutex will lock our threads, until a new line is read and is ready
to be parsed. */
std::mutex mutex;
/* This condition variable is responsible for alerting mutex when things are
ready. */
std::condition_variable processCondition;
std::ifstream::pos_type fileSize; // Total file size used for the status meter.
std::string help = "Usage: parsewinelog [yourlog.txt]"; // --help output.
Nothing magic here, though you will probably frown on the std::condition_variable if you have never used those before. Simply put (very simply put), they are used to wait on a mutex, which will block a thread until notified. You can do sophisticated things with them, but this is my first experiment so I kept it as simple as possible.
In an effort to keep things simple, I do not check for spurious wake-ups. It is critical you do so in a real application. More information on how to do that can be found in this blog. I highly recommend the read, as it’s one of the nicer blogs on c++ multi-threading.
File stuff and fancy progress bar
/* We need to know the total file size so we can output the progress meter. */
std::ifstream::pos_type getFilesize(const std::string& filename)
{
std::ifstream in(filename, std::ifstream::ate | std::ifstream::binary);
return in.tellg();
}
/* This is the progress bar. Mostly copied from
https://www.ross.click/2011/02/creating-a-progress-bar-in-c-or-any-other-console-app/ */
static inline void progressBar(unsigned int x, unsigned int n, unsigned int w = 50)
{
if ( (x != n) && (x % (n/100+1) != 0) ) return;
float ratio = x/(float)n;
int c = ratio * w;
std::cout << std::setw(3) << (int)(ratio*100) << "% [";
for (int x=0; x<c; x++) std::cout << "=";
for (int x=c; x<w; x++) std::cout << " ";
std::cout << "]\r" << std::flush;
}
/* A simple function to open the read file. */
std::ifstream openInFile(const std::string& f)
{
std::ifstream inFile(f, std::ios::in);
if (!inFile.is_open()) {
std::cout << "Couldn't read input file: " << f << std::endl;
inFile = std::ifstream();
} else {
fileSize = getFilesize(f);
std::cout << "Parsing: " << f
<< " -- Filesize: " << fileSize/1048576 << " MB"
<< std::endl;
}
return inFile;
}
/* A simple function to open the output file. */
std::ofstream openOutFile(std::string f)
{
auto extPos = f.find_last_of(".");
std::string extension = f.substr(extPos);
std::string outFilename = f.substr(0, extPos);
f = outFilename + "_parsed" + extension;
std::ofstream outFile(f, std::ios::out);
if (!outFile.is_open()) {
std::cout << "Couldn't create output file: " << f << std::endl;
outFile = std::ofstream();
}
return outFile;
}Again, nothing new here, other than this fantastic progress bar. Thank you Mr. Ross Hemsley :)
main()
/* Our main software, we will:
Open the input file, create the output file.
Read the input file, create functor parser objects.
Notify the threadpool that when a new line is ready for parsing.
Print a progress bar.
Finally output the remaining parser objects in the output file.
Close the open files.
...
profit */
int main(int argc, char** argv)
{
/* Print Help */
if (argc != 2) {
std::cout << help << std::endl;
return 0;
}
/* Initialize */
std::string filename = std::string(argv[1]); // Filename is first argument.
std::ifstream inFile = openInFile(filename); // Open input log.
std::ofstream outFile = openOutFile(filename); // Open output file for writing.
/* Create the ThreadPool object. This contains our threads (on my
laptop 7 threads), and takes care of distributing the work load. */
ThreadPool workerPool;
/* This string is allocated for every line. It is a major performance
hit. */
std::string line;
/* Read input file, queue the calls, process the rets or add to
finale output. */
while (getline(inFile, line)) {
/* The line is a Call. This is a future work object. Add it to
the thread pool to be eventually processed. */
if (line.find("Call") != std::string::npos) {
workerPool.enqueue(std::move(line));
/* The line is a ret. Process the stored calls to match the
return line. This will trigger the work (our condition variable). */
} else if (line.find("Ret") != std::string::npos) {
workerPool.process(std::move(line));
/* This is not a line we can parse. Add it to the output log.
TODO: To make this sofware really useful, we should store the
line numbers and output the final result "in sequence". */
} else {
outFile << line << std::endl;
}
/* The nifty progress bar by Ross Hemsley. We divide the postion
by 100 since the files are so big, we weren't hitting the
update treshold enough. */
progressBar((inFile.tellg()/100) + 1, fileSize/100);
}
/* Finalize */
std::cout << std::endl << "Lines left: " << workerPool.size()
<< " -- Outputting to file." << std::endl; // Alert user.
/* Write all the remaining work to the output file. These are the
"calls" that weren't matched with "ret"urns. */
outFile << workerPool;
return 0;
}Allright! Things are getting interesting. Understanding the main is essential to understanding the thread portions. I believe the code is quite direct and “to-the-point”. We read the whole input file, line by line, and queue up “Calls” or process “Rets”. I add std::move as an indicator of my intent. It is not necessary, but indicates that *moving *the strings is part of the design, not an after thought. The “Ret” lines are also moved into the ThreadPool, where they will be copied to all the threads. Talking about thread pools…
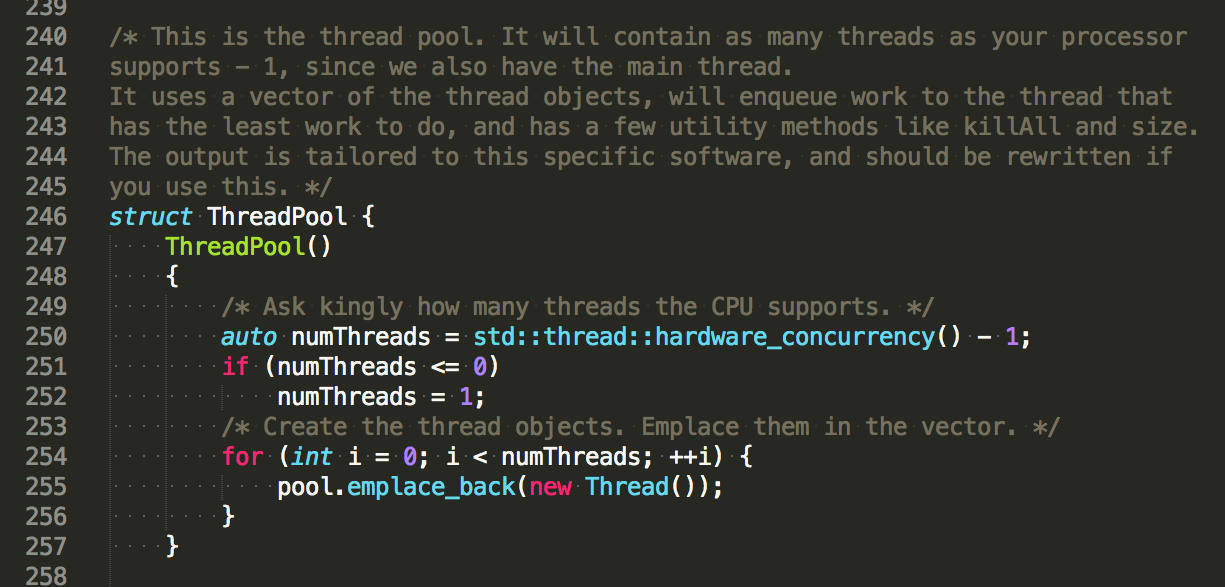
ThreadPool
/* This is the thread pool. It will contain as many threads as your processor
supports - 1, since we also have the main thread.
It uses a vector of the thread objects, will enqueue work to the thread that
has the least work to do, and has a few utility methods like killAll and size.
The output is tailored to this specific software, and should be rewritten if
you use this. */
struct ThreadPool {
ThreadPool()
{
/* Ask kingly how many threads the CPU supports. */
auto numThreads = std::thread::hardware_concurrency() - 1;
if (numThreads <= 0)
numThreads = 1;
/* Create the thread objects. Emplace them in the vector. */
for (auto i = 0; i < numThreads; ++i) {
pool.emplace_back(new Thread());
}
}
/* Loop over the threads in a "horizontal" manner, assuming the work
was well balanced and is somewhat still in order.
FIXME: A better way of outputting sequentially would be to store the
line number, and output according to that. */
friend std::ostream& operator<<(std::ostream& os, ThreadPool& tp)
{
int i = 0;
while (!tp.pool.empty()) {
/* This will unlock the thread, more info below. */
if (tp.pool[i]->size() == 0) {
i = tp.killThread(i);
continue;
}
os << *(tp.pool[i]); // Print to file.
i = (i + 1) % tp.pool.size(); // Loop de loop.
}
return os; // Never forget!
}
/* This was a major problem. The threads were stuck waiting on their
mutexes and the condition variable. So here we need to first, switch
the running bool to stop, then unlock all the mutexes so the thread
completes its "infinit" work loop. */
int killThread(const int& i)
{
pool[i]->stop(); // Notify the thread it is done, pat on back.
processCondition.notify_all(); // Triggers the conditional var.
pool.erase(pool.begin() + i); // Remove the pool from our vector.
return i < pool.size() ? i : 0; // Return the next thread.
}
/* Utility method to kill all the threads. Unused. */
void killAll()
{
for (const auto& x : pool) {
x->stop();
}
processCondition.notify_all();
}
/* This is where we add work. We will check which thread has the least
amount of work to distribute the work-load. */
void enqueue(std::string call)
{
/* next points to the least busy thread. */
auto next = std::min_element(pool.begin(), pool.end(),
[](const std::unique_ptr<Thread>& i,
const std::unique_ptr<Thread>& j)
{ return i->size() < j->size(); });
(**next).addCall(std::move(call)); // Add work.
}
/* Notify all threads they can process their queued up work. This
effectivily unlocks their mutexes (once) using a conditional variable.
We lock_guard in case the threads are still working. */
void process(std::string line)
{
std::lock_guard<std::mutex> lock(mutex); // Threads aren't ready.
for (const auto& x : pool) {
x->processLine(line); // Line is NOT moved.
}
processCondition.notify_all(); // Get to work!
}
/* Utility, how many objects are queued for work. */
int size()
{
int ret = 0;
for (const auto& x : pool) {
ret += x->size();
}
return ret;
}
/* We use unique_ptr because there where major move semantics issues.
Since the only real work in the thread pool is figuring out which thread
is available, memory data alignement is not as important. */
std::vector<std::unique_ptr<Thread>> pool;
};The thread pool is our “thread managemer” if you will. It distributes work across the threads, constructs or kills the thread objects. I have a few useful methods in there, that I didn’t specifically need for my current software. There are many ways to design this, maybe some are more efficient than others.
Thread Object
/* The actual thread. This guy contains a vector of work functors. Here we are
parsing strings. I couldn't use a vector of std::function as I need to store
a parameter inside, and later process that. A function object seemed
more appropriate. */
struct Thread {
/* WARING: If you have other member assignements, the thread
construction would be in another method, and called AFTER the
constructor. */
Thread() { myThread = std::thread(&Thread::run, this); }
/* If this is called before the thread is done, your software will hang. */
~Thread() { myThread.join(); }
/* Our final output method. We lock_guard on an internal mutex in case
things went bad and the thread hasn't finished working. More than likely
processing it's "last run". */
friend std::ostream& operator<<(std::ostream& os, Thread& t)
{
std::lock_guard<std::mutex> lk(t.vectorMutex); // Don't explode.
os << t.parseVector[0].Call << std::endl; // Output remaining call.
t.parseVector.erase(t.parseVector.begin()); // Yes yes I know...
return os; // Never forget!
}
/* This is our working state: wait till we are ready to work,
get notified we are, do work, rince repeat. Lock on an internal mutex
in case work is still getting queued up. */
void run()
{
while(running) {
/* Wait to be notified. */
std::unique_lock<std::mutex> lock(mutex);
/* Very simple conditon variable example. */
processCondition.wait(lock);
/* Vector is free? */
std::lock_guard<std::mutex> lk(vectorMutex);
for (int i = 0; i < parseVector.size(); ++i) {
/* The functor returns true if the call was
matched. */
if (parseVector[i](currentWork)) {
/* I know. But data oriented design.
Do some performance analysis and see how
this really isn't a bottle-neck. */
parseVector.erase(parseVector.begin() + i);
/* We know that we only have to match 1
call.
TODO: We could notify other threads they
are also done.*/
break;
}
}
}
}
/* Utility */
void stop()
{
running = false;
}
/* Create a function object, move the call string in it. */
void addCall(std::string call)
{
std::lock_guard<std::mutex> lk(vectorMutex); // Just in case.
parseVector.push_back(Parser(std::move(call)));
}
/* The string to process is copied inside the thread. */
void processLine(std::string line)
{
currentWork = line;
}
/* Utility */
int size()
{
return parseVector.size();
}
bool running = true; // We start running.
std::string currentWork; // The copied string to process.
std::thread myThread; // Our thread.
std::mutex vectorMutex; // Inner mutex to prevent explosions.
/* We store the functors contiguously in a vector, as this will REALLY
improve the performance. No Pointers Allowed. */
std::vector<Parser> parseVector;
};Using an object to encapsulate a thread grants many benefits. For starters, it is a very “visual” or “sound” way of thinking about threads. You do not need to change how you imagine your code, this fits right in with what you are used to. Create the object: create the thread. Destroy the object: thread is stopped.
Here is a good blog with some more information about the subject. In the end, I do not see why I wouldn’t use the thread-object analogy, unless I am dealing with very simple things, or a single temporary thread spawned. Other than that it “just makes sense”.
I will say it again, storing the objects contiguously in a vector is a major performance boost. I hope most C++ programmers are well aware of the Data Oriented Design paradigm benefits. This will take advantage of your processor cache and minimize cache-misses. How well it works in a threaded environment depends on your CPU family.
/* Our actual work. Since the software requires to store the call, and later
process it, we don't use std::function. Of course that would be a nicer way
to go about it. All this does is either store a string, or compare the member
string with another. */
struct Parser {
/* Store the payload. */
Parser(std::string call) : Call(call) {}
/* Process the payload*/
bool operator()(const std::string& Ret) const
{
/* Check the call match. This "cleaning" could be done in the
constructor, but I put it here. As the performance bottleneck
is expected to be all in this method. */
auto callPosBegin = Call.find("Call ") + 5;
auto callPosEnd = Call.find_first_of('(') - callPosBegin;
std::string funcCall = Call.substr(callPosBegin, callPosEnd);
/* Do we match the "ret"urn? This is the single most expensive
operation of the entire software! */
if (Ret.find(funcCall) == std::string::npos)
return false;
/* Check return address, if it exists. */
auto addrPosBegin = Call.find("ret=");
/* There was no return address, assume we match the string.
Another expensive operation, but not so bad. */
if (addrPosBegin == std::string::npos)
return true;
addrPosBegin += 4;
std::string addr = Call.substr(addrPosBegin); // Get the return address.
/* Do we also match the address? Another expensive operation. */
if (Ret.find(addr) == std::string::npos)
return false;
return true;
}
std::string Call;
};And finally we have the simple parser functor. All it does is return true if it found a matching return call. If so, it will be removed from the workload.
I hope you find this useful, at least as a working example of how to use std::thread, simple thread pools and a thread object.
As always, the project is available on my github.